





В чём разрыв между тем, что записано в CRM, и тем, что компания на самом деле знает о клиентах
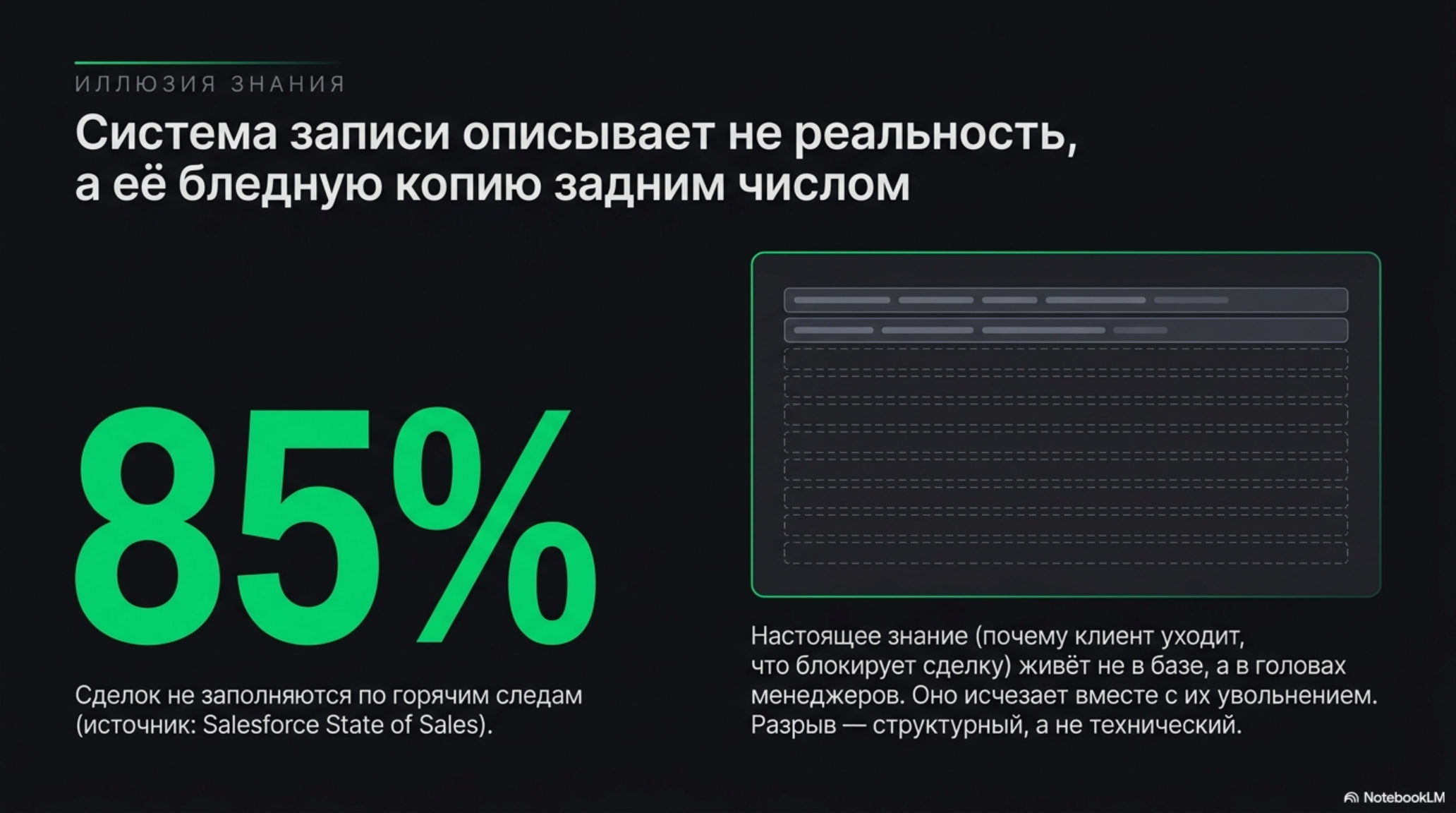
По данным Salesforce State of Sales, значительная часть продавцов не вносит данные в CRM вовремя — оценки крутятся вокруг отметки 85% незаполнения по горячим следам. Это значит, что система, в которую компания вложила годы и бюджеты, по факту описывает не реальность сделок, а её бледную копию задним числом. Контакт, сделка, статус, заметка — всё внесено выборочно, неполно, с опозданием. Настоящее знание о том, почему клиент уходит, что блокирует сделку, какой паттерн предшествует отказу, живёт не в базе, а в головах менеджеров и исчезает вместе с их увольнением. Разрыв здесь не технический. Это разрыв между системой записи (system of record) и пониманием.
Почему попытка закрыть разрыв заменой CRM почти всегда проваливается
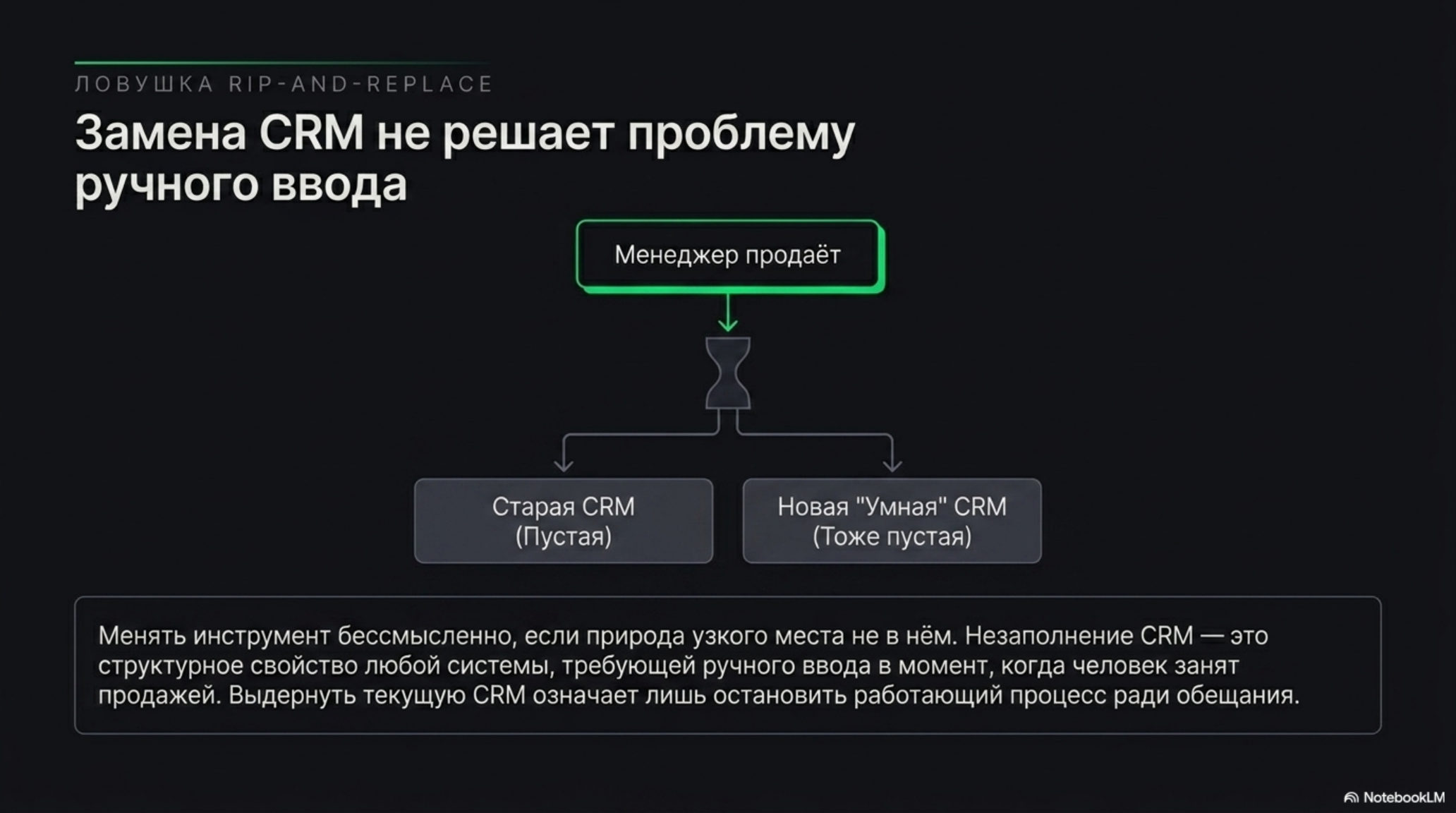
Соблазн очевиден: если CRM пустая, давайте заменим её на «умную». Эта логика приводит традиционный B2B к проектам rip-and-replace, которые проваливаются по одной и той же причине. CRM в зрелой компании — это не база данных, это поверхность, на которой держится дисциплина отдела продаж: pipeline, статусы, задачи, история. Люди привыкли к этому интерфейсу, регламенты написаны под него, отчётность собирается из него. Выдернуть его означает остановить работающий процесс ради обещания, что новый будет лучше.
Проблема в том, что замена CRM не решает исходную задачу. Новая система так же останется таблицей фактов, которую так же не будут заполнять вовремя. Незаполнение CRM — это не дефект конкретного продукта, это структурное свойство любой системы, которая требует от человека ручного ввода в момент, когда он занят продажей. Та же Salesforce State of Sales фиксирует ручной труд по администрированию данных как одну из главных причин, по которой продавцы тратят на собственно продажу меньше трети рабочего времени, — смена ярлыка на системе этого не меняет. Менять инструмент бессмысленно, если природа узкого места не в инструменте.
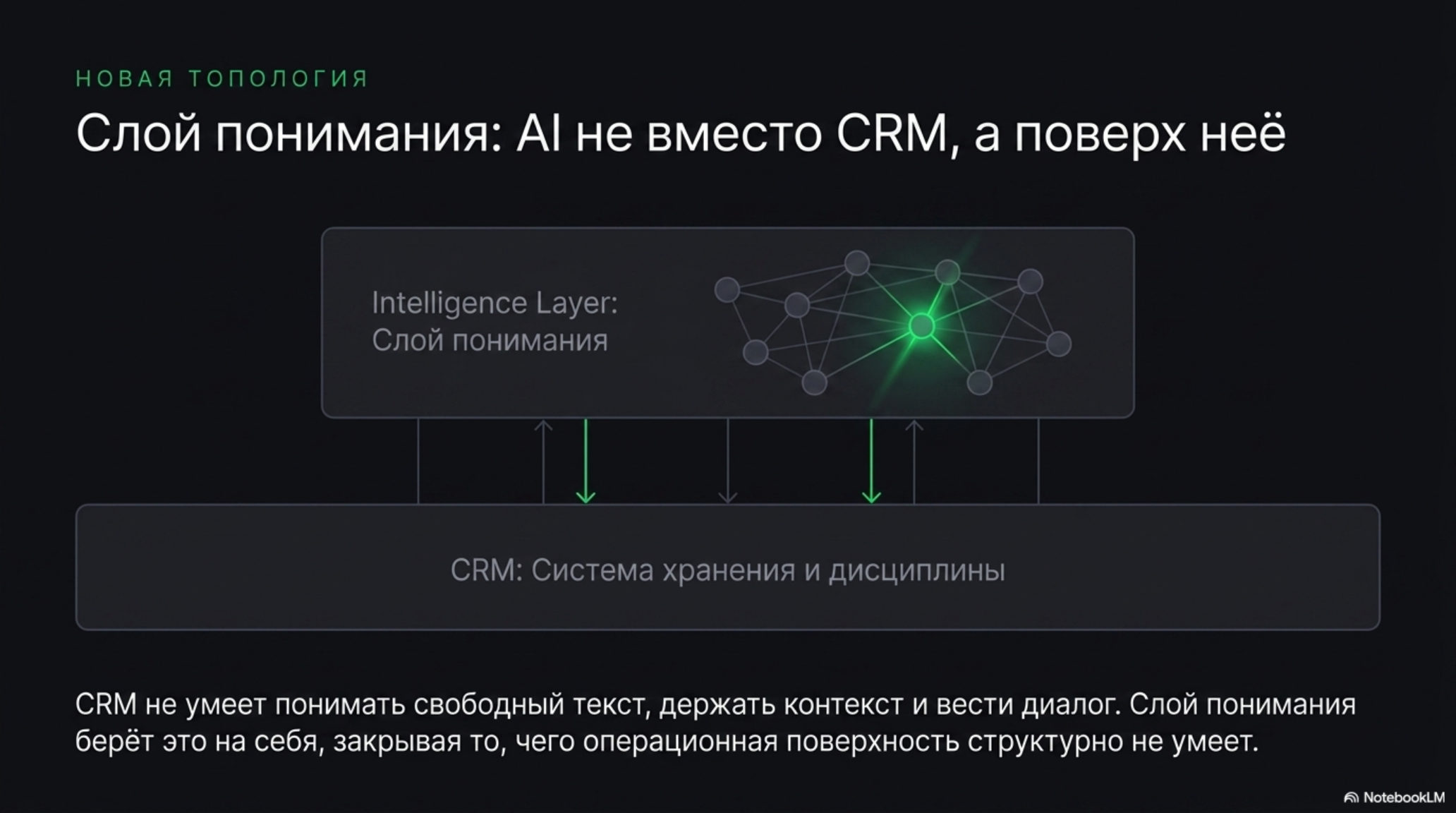
Правильный вопрос звучит иначе. Не «бот или CRM» и не «какую CRM выбрать», а «какая операционная поверхность у клиента уже есть, и как надстроить над ней слой, который закроет то, чего она структурно не умеет». CRM умеет хранить и дисциплинировать. Она не умеет понимать свободный текст, вести диалог, держать контекст и работать как постоянно доступный собеседник. Именно сюда заходит AI — не вместо, а поверх.
Три типа памяти, которые превращают пассивную базу в актив
Слой понимания (intelligence layer) поверх CRM отличается от CRM не наличием модели, а способом накопления знания. CRM заполняется руками. Слой понимания заполняется пассивно — из самих диалогов, событий и исходов. Академический обзор «Memory in the Age of AI Agents» описывает память агента как несколько разных слоёв, и эта разбивка прямо ложится на задачу.
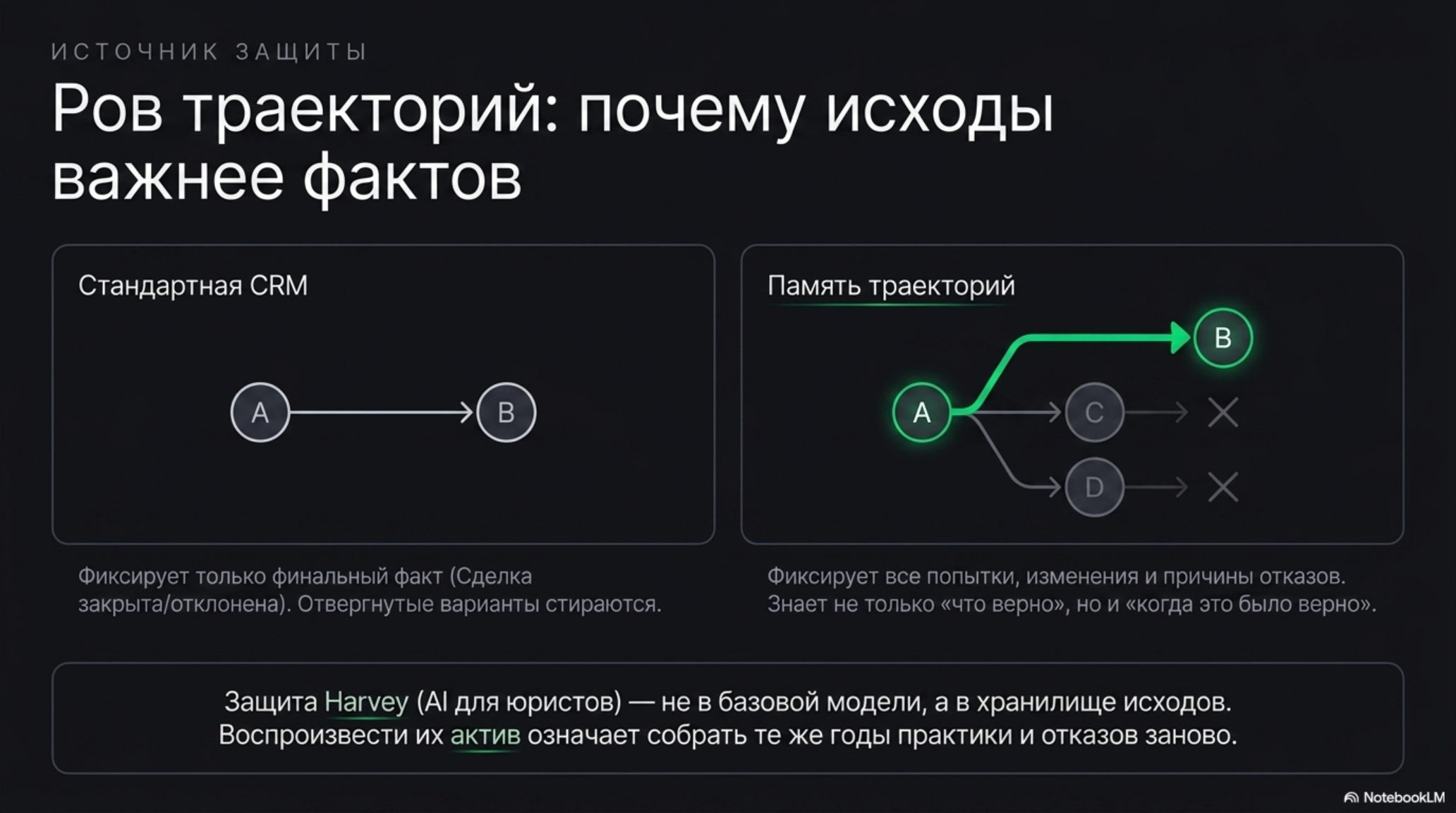
Первый слой — эпизодическая память: что произошло, в каком порядке, с каким контекстом. Кто написал, когда, что попросил, что ответили. Второй — семантическая: что это значит. Профили клиентов, повторяющиеся ситуации, типичные возражения и то, как они разрешались. Третий — процедурная: как мы это делаем. Правила принятия решений, выведенные из практики, а не записанные в документ. Четвёртый, самый ценный и почти нигде не инструментированный, — память траекторий: что агент предложил, что человек изменил, какой получился исход. Этого нет ни в одной CRM, потому что CRM не фиксирует, что было отвергнуто и почему.
Разница принципиальная. RAG (retrieval-augmented generation, генерация с поиском по документам) — это умный поиск: задаёшь вопрос, система достаёт релевантные фрагменты. Он улучшает точность ответа, но не понимает причинно-следственных связей между событиями. Слой понимания строит не индекс документов, а компактную модель операционной реальности бизнеса — модель мира (world model), — которая выводится из опыта. Тот же обзор фиксирует память не как функцию-приятную-добавку, а как базовую способность агентов. Для длинного цикла это критично: цена и доступность вчера не равны цене и доступности сегодня, и хранилище должно знать не только «что верно», но и «когда это было верно».
Как слой замыкается на CRM, не ломая её: шина событий вместо новой системы
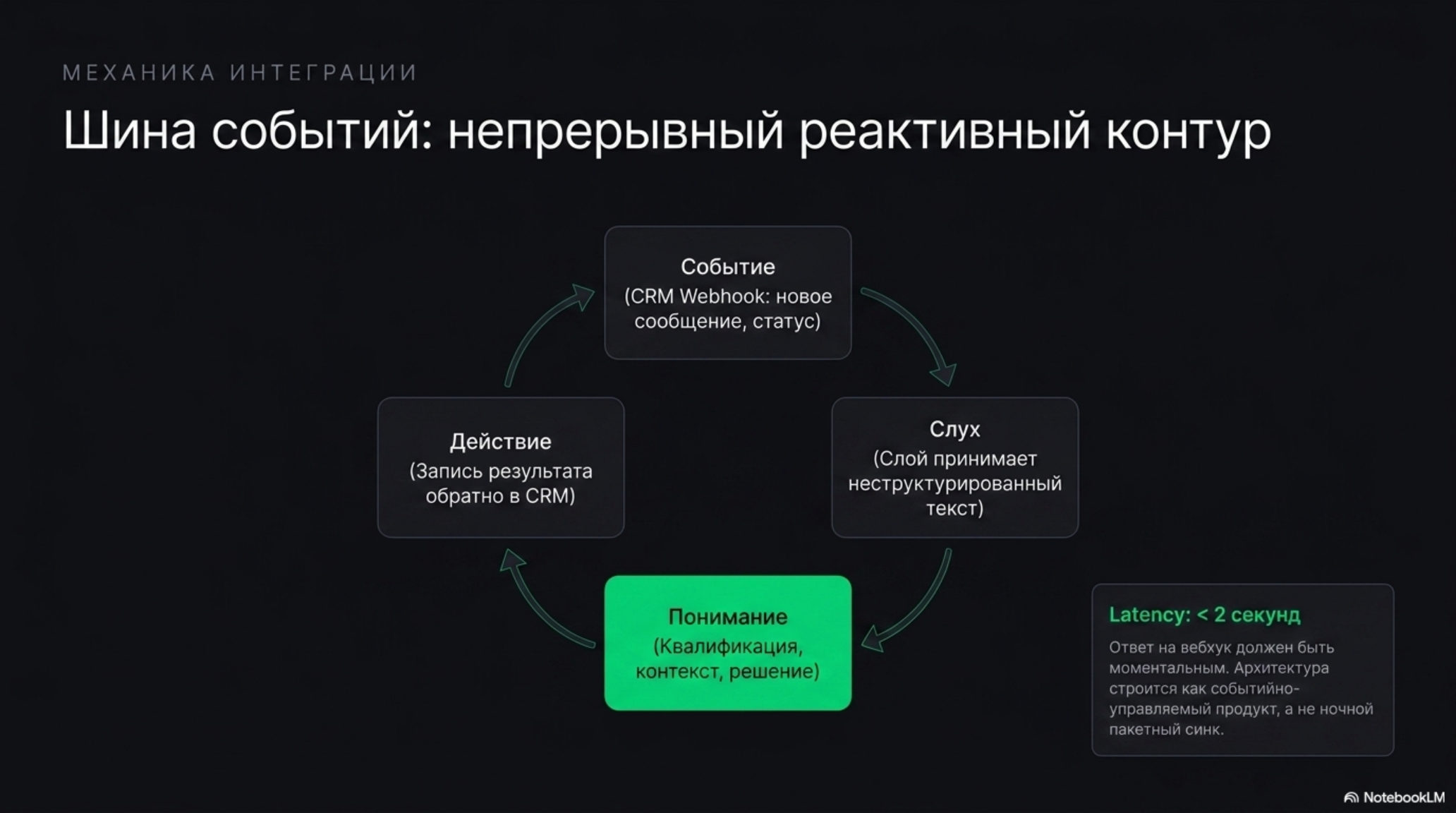
Архитектура, которая работает, не подменяет CRM, а встраивается в её событийный поток. Современные CRM отдают события через вебхуки: новое сообщение, смена статуса, новый лид, новая задача. Это превращает CRM в шину событий (event bus), к которой подключается слой понимания. Он слушает входящий свободный текст, квалифицирует, задаёт уточняющие вопросы, переводит разговор в следующее разумное действие и пишет результат обратно в CRM — туда, где живёт менеджер.
У этой схемы есть жёсткое инженерное требование. Ответ на вебхук обычно нужен быстрее, чем за пару секунд, иначе интеграция начинает деградировать. Платформы слоя поверх CRM строятся именно как событийно-управляемые продукты с коннекторами к системе записи, а не как ночной синк — это видно по архитектуре Salesloft, который продаёт оркестрацию выручки поверх Salesforce и HubSpot как отдельный реактивный слой. Значит, слой должен быть событийно-управляемым и надёжным, а не пакетным ночным процессом. Это не «добавить чат-бота сбоку» — это построить постоянно доступный реактивный контур поверх системы записи.
Здесь важно отличить слой понимания от транспортных сервисов, которые формально тоже «надстройка над CRM». Платформы передачи сообщений — мессенджер-агрегаторы, коннекторы каналов — переносят текст из WhatsApp или Telegram в карточку сделки. Они не дают reasoning, не квалифицируют автономно, не накапливают модель мира. Это инфраструктурный слой, и он уже занят и коммодитизирован. Слой понимания живёт на уровень выше: он не доставляет сообщение, он понимает его и принимает контекстное решение. Если AI остаётся только транспортным ботом без записи в pipeline, он не становится операционным слоем — но и CRM без AI остаётся пассивной базой, которая сама не двигает диалог.
Где здесь защита: не модель, а глубина и накопленные данные
Главное возражение к этому паттерну — «AI массовый, любой повторит за полгода». Возражение верное наполовину, и понимание границы важнее самого паттерна. Промпты переносимы: SaaStr в разборе «4 уровня переносимости промптов» фиксирует, что значительная часть AI-агентов копируется конкурентом за дни через перенос промпта и пару дней донастройки. Базовая модель тоже не защита: Foundation Capital в «When model providers eat everything» прямо описывает, как провайдеры моделей идут вверх по стеку и съедают прикладной слой, у которого нет ничего, кроме обёртки. Стандартизация управляемых сред дополнительно обнуляет ценность инфраструктурной части — открытые протоколы вроде Model Context Protocol делают подключение инструментов вопросом настройки, а не инженерии.
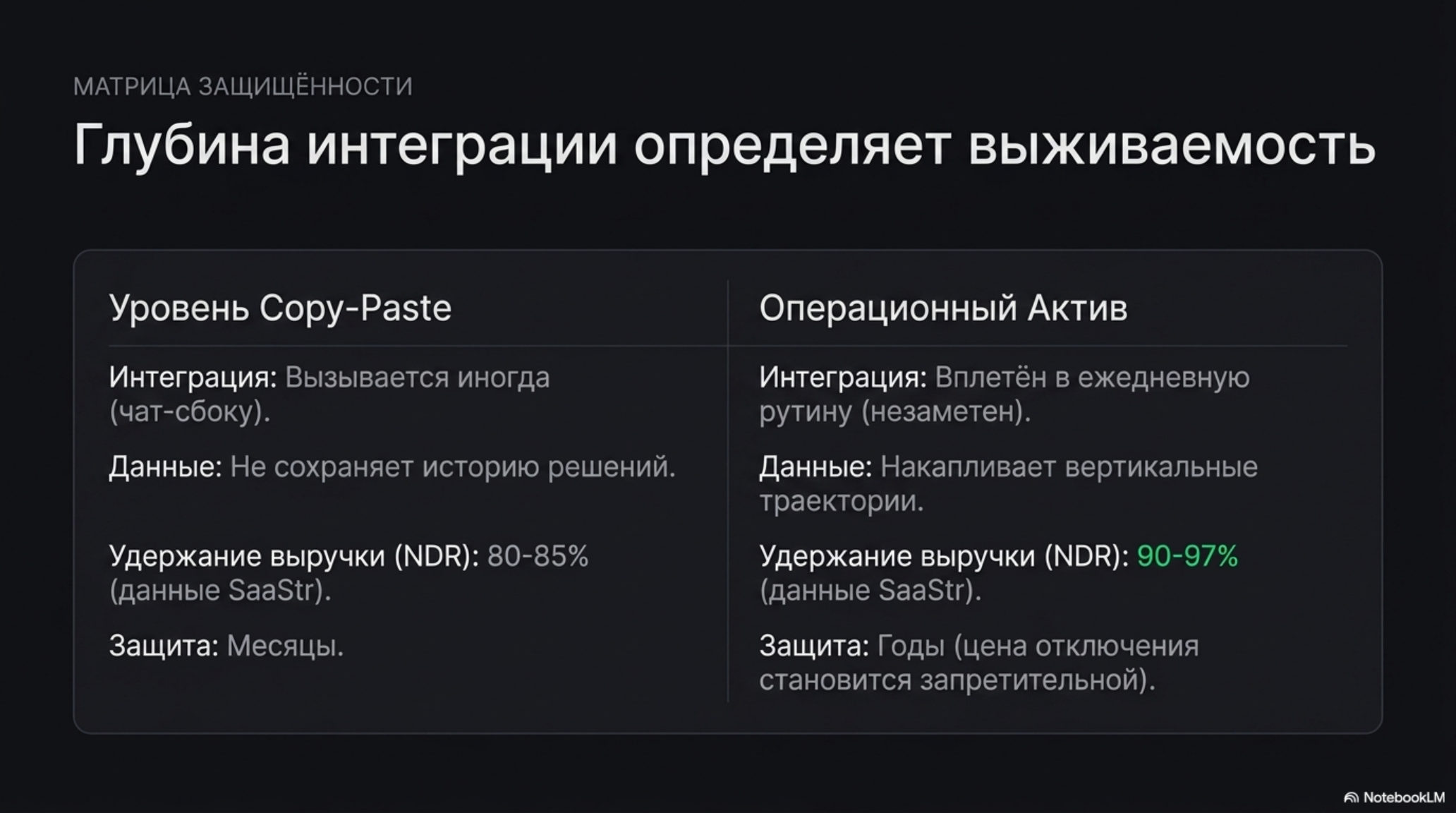
Защита лежит в трёх других местах. Первое — глубина интеграции в ежедневную рутину. SaaStr в обзоре «Follow the agents» разводит уровни приживаемости: агенты уровня copy-paste промптов удерживают валовую выручку на уровне 80-85%, агенты, встроенные в рабочий процесс и домен, — 90-97%. Разница не в качестве модели, а в том, насколько глубоко слой вплетён в операции. Второе — вертикальные данные: накопленные траектории решений в конкретной отрасли, которые конкурент должен собирать с нуля. Третье — владение рабочим процессом: если при отключении слоя останавливается часть бизнеса, цена ухода становится запретительной.
Каноничный пример — Harvey в юриспруденции. Защита там не в том, что они используют сильную модель, — модель доступна всем. Защита в том, что их хранилище копит не документы, а решения с исходами, и встроено в ежедневный рабочий цикл юриста, а не вызывается иногда. Воспроизвести это означает собрать те же годы практики заново. SaaStr формулирует водораздел резко: CRM, которая становится хабом для AI-агентов, выигрывает, а та, что не становится, превращается в базу данных, за которую вы переплачиваете. Защищён не AI и не CRM по отдельности — защищён слой, который накапливается между ними и принадлежит конкретному бизнесу.
Что это значит на практике
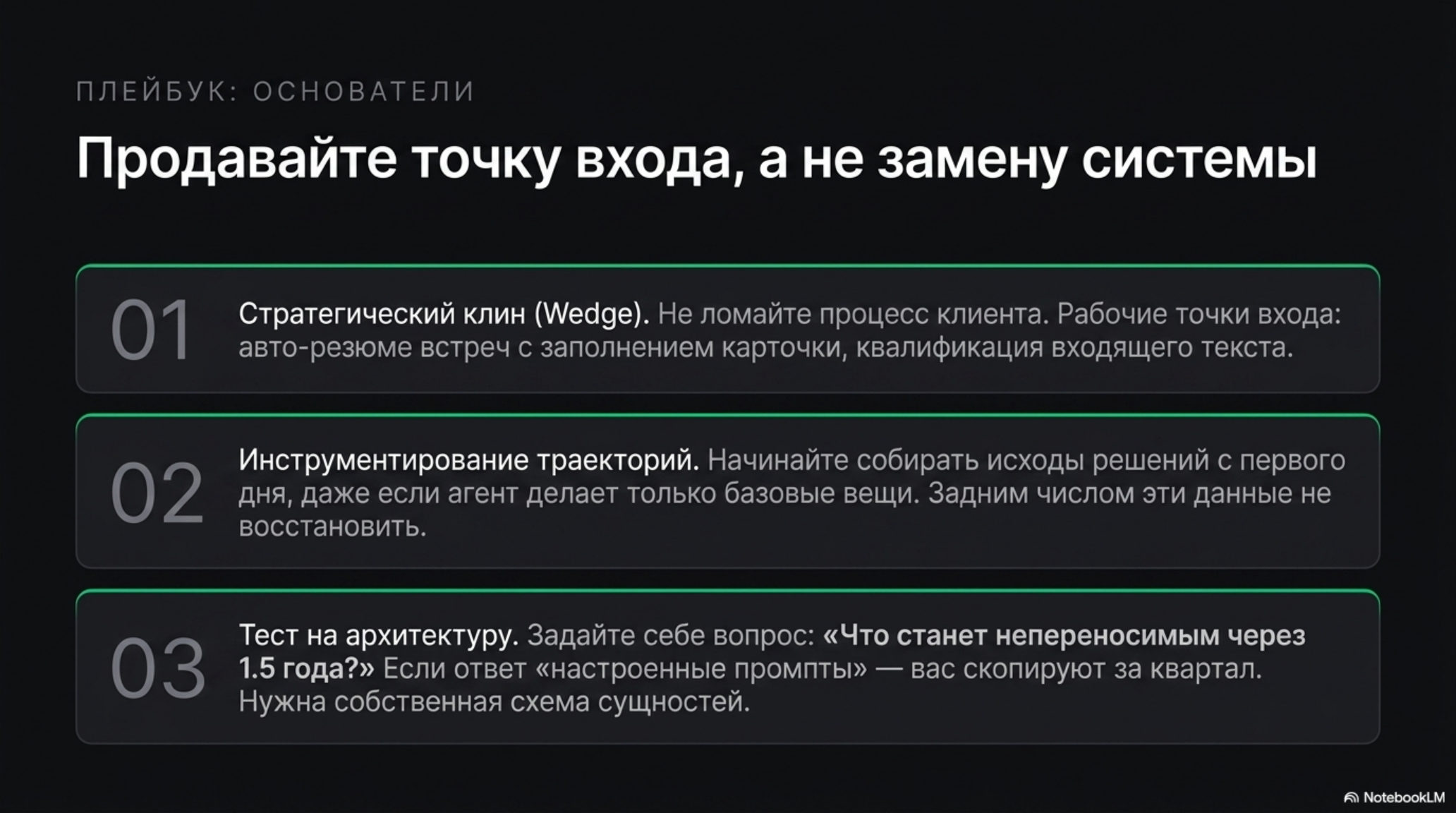
Для основателя, который строит продукт в традиционном B2B: не продавайте замену CRM. Продавайте точку входа (wedge), которая загорается быстро и не требует от клиента ломать процесс. Рабочие точки входа — резюме встречи с автозаполнением карточки и следующим шагом, реактивация зависших сделок по контексту истории, квалификация входящего свободного текста. Тест на правильную архитектуру один: что именно у клиента станет уникальным и непереносимым через полтора года работы. Если ответ — «настроенные промпты и коннекторы», вы строите обёртку, которую скопируют за квартал. Если ответ — собственная схема сущностей отрасли плюс история траекторий решений плюс кодифицированные регламенты, вы строите актив. Инструментировать накопление траекторий нужно с первого дня, даже если агент пока делает три вещи: задним числом эти данные не восстановить.
Для руководителя традиционной компании, у которого CRM уже стоит и не заполняется: не меняйте CRM. Оцените её как операционную поверхность и спросите поставщика слоя понимания, как он встраивается в её событийный поток, не требуя миграции. Полезный тест на старте: попросите показать, где физически хранятся накопленные данные диалогов и решений и в каком формате вы можете их забрать. Если данные живут только в управляемой среде провайдера и их ценность неотделима от его инфраструктуры — вы покупаете не актив, а зависимость. Второй тест — латентность: слой обязан отвечать на событие за секунды, иначе он рассыпется на реальной нагрузке. И отдельно — ежемесячное сопровождение здесь не «поддержка», а процесс накопления интеллекта бизнеса: каждый месяц работы — это новые траектории и растущая стоимость ухода. Такой слой — приём и квалификация заявок поверх amoCRM, без замены самой CRM — у нас стоит в нише модульных домов: открыть кейс.
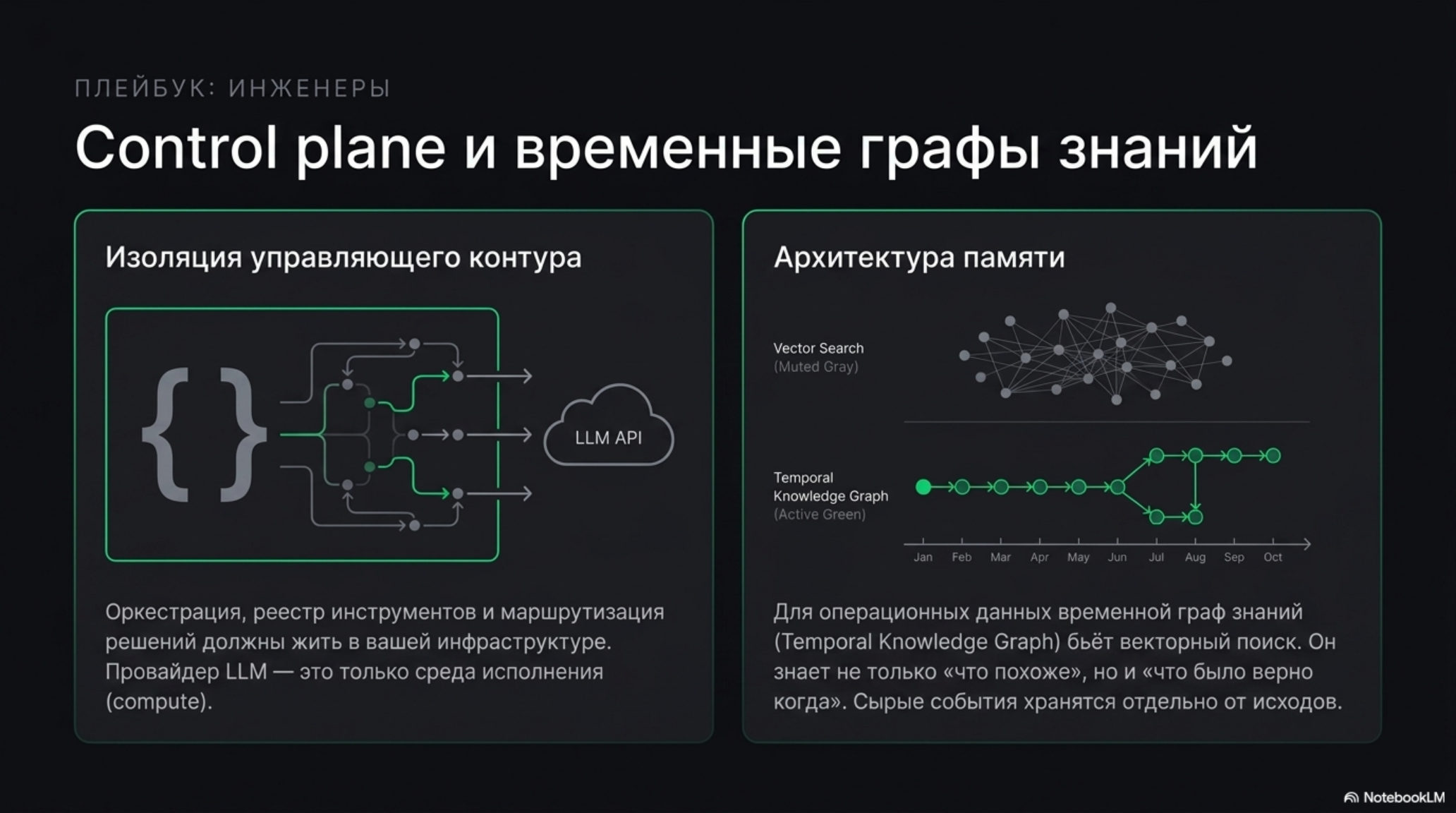
Для инженера, проектирующего такой слой: ключевой вопрос — где живёт управляющий контур (control plane). Если оркестрация, реестр инструментов и маршрутизация решений описаны в вашем коде и развёрнуты в вашей инфраструктуре, вы используете провайдера как среду исполнения, а не как операционную платформу. Память делите на два хранилища: сырые события и отдельно траектории решений с полем исхода — именно второе не должно утекать к провайдеру модели и именно оно создаёт защиту. Для операционных данных, где факты меняются во времени, временной граф знаний бьёт обычный векторный поиск: он знает не только «что похоже», но и «что было верно когда».
На что смотреть дальше
Паттерн воспроизводим везде, где у бизнеса уже есть операционная поверхность и длинный цикл: автодилеры, недвижимость, поддержка SaaS, проектные продажи, любой традиционный B2B. Сигнал, что слой понимания приживается как самостоятельная категория, — появление поставщиков, которые продают именно его, а не «AI внутри нашей CRM». Параллельно стоит следить за горизонтальными CRM: они добавят generic-AI поверх себя, и это случится, но с отставанием на полтора-два года и без вертикальной глубины. Окно для вертикального слоя понимания — этот зазор. Поставщики вроде Salesloft давно продают слой поверх CRM как отдельный продукт, но горизонтально и по англоязычному рынку; вертикальные ниши с длинным циклом этот слот пока держат открытым. Кто построит в нём актив, а не обёртку, тот и удержит клиента, когда модель станет массовой.
Главное
- CRM остаётся таблицей фактов: по данным Salesforce около 85% продавцов не заполняют её вовремя, и реальное знание о клиентах живёт в головах, а не в базе.
- Замена CRM не решает проблему — новая система так же не будет заполняться. Правильный ход — надстроить слой понимания поверх существующей поверхности.
- Слой копит знание пассивно через четыре типа памяти (эпизодическую, семантическую, процедурную и траекторий) и пишет обратно в CRM через её шину событий, требуя ответа за секунды.
- Защита не в модели — она массовая через 12-24 месяца — и не в CRM, а в глубине интеграции, вертикальных данных и владении рабочим процессом. SaaStr фиксирует разрыв в удержании: 80-85% против 90-97%.
- Паттерн воспроизводим в любом традиционном B2B с длинным циклом, где операционная поверхность уже существует.
FAQ
Чем слой понимания отличается от обычного чат-бота на CRM? Чат-бот доставляет и пересылает сообщения, не накапливая знание о бизнесе. Слой понимания квалифицирует входящий свободный текст, держит контекст, принимает контекстные решения и пассивно строит модель операционной реальности компании из диалогов и исходов. Бот без записи в pipeline остаётся транспортом, слой — становится операционным активом.
Почему нельзя просто заменить CRM на AI-native систему? Незаполнение CRM — структурное свойство ручного ввода, а не дефект конкретного продукта. Новая система так же не будет заполняться вовремя. К тому же зрелая CRM держит дисциплину отдела продаж, и её замена останавливает работающий процесс ради обещания. Надстройка снимает узкое место, не ломая поверхность.
Если модели коммодитизируются, что мешает конкуренту повторить слой за полгода? Промпты и базовая модель действительно переносимы за дни-недели. Не переносятся накопленные траектории решений в конкретной отрасли, собственная схема сущностей и глубина встраивания в ежедневный процесс. Конкурент получит обёртку, но не годы накопленного знания — именно это даёт разрыв в удержании 80-85% против 90-97% по данным SaaStr.
Как технически слой связан с CRM? Через событийный поток. CRM отдаёт вебхуки на новое сообщение, смену статуса, новый лид. Слой подключается к этому потоку как к шине событий, реагирует за секунды и пишет результат обратно в карточку. Это событийно-управляемая архитектура, а не ночной пакетный синк.
В каких отраслях паттерн работает? В любом традиционном B2B с длинным циклом, где у бизнеса уже есть операционная поверхность: автодилеры, недвижимость, проектные продажи, поддержка SaaS. Условие одно — существует система, в которой команда живёт ежедневно, и есть знание о клиентах, которое сейчас теряется между этой системой и головами сотрудников.